Review and Retrospective – Part 3
1. Introduction
2. Agile Periodization and Philosophy of Training
3. Exercises – Part 1 | Part 2
4. Prescription – Part 1 | Part 2 | Part 3
5. Planning – Part 1 | Part 2 | Part 3 | Part 4 | Part 5 | Part 6
6. Review and Retrospective – Part 1 | Part 2 | Part 3
Review and Retrospective in different time frames
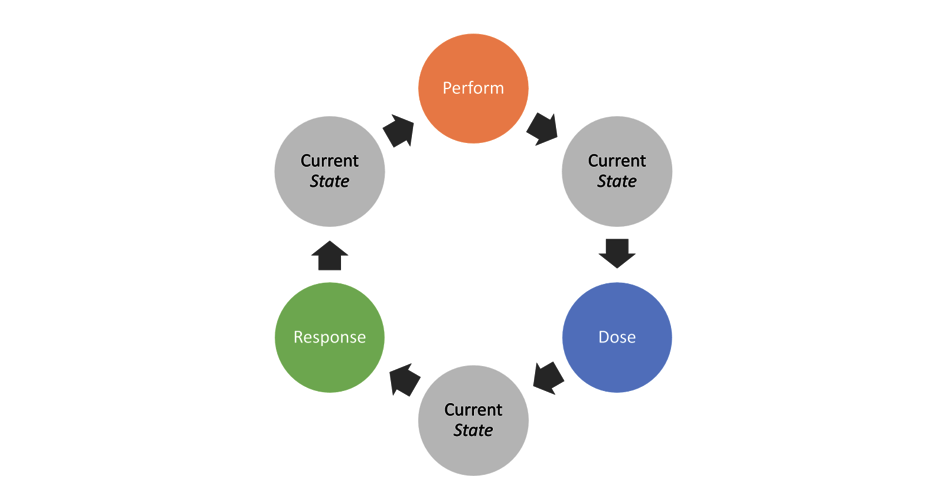
Review and Retrospective represents two “inspect and adapt” components with distinct purposes (Figure 6.22) (Rubin, 2012; Stellman & Greene, 2014; Sutherland, 2014; Layton & Ostermiller, 2017; Layton & Morrow, 2018). If you check Figure 2.13 from Chapter 2, Review and Retrospective would correspond to check and adjust components of the Deming’s cycle (Figure 6.23). Review is about demonstrating the performance (which can be considered testing or the analysis of the response) while comparing it to expected performance or outcome/performance goals or objectives. Retrospective is about understanding and improving the process underlying performance (which can be considered analysis of the dose, current state and plan and how it affects the response). Retrospective is also trying to answer following questions:
What worked well?
What can be improved?
What will we commit doing in the next iteration?
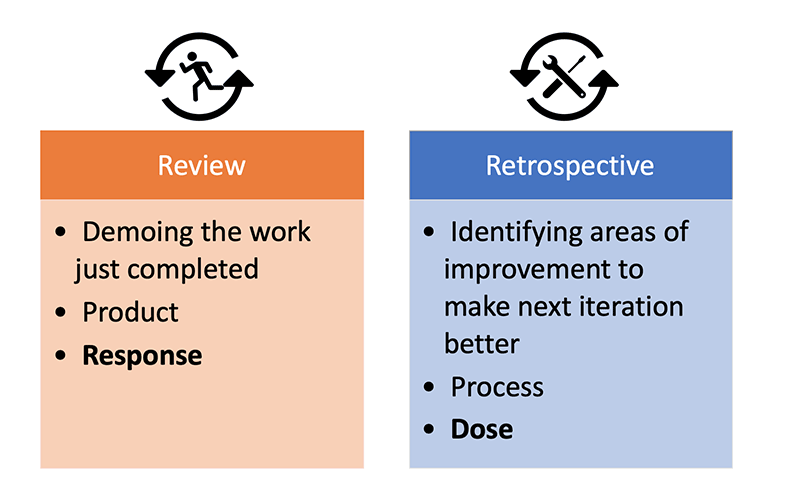
Figure 6.22. Review and Retrospective
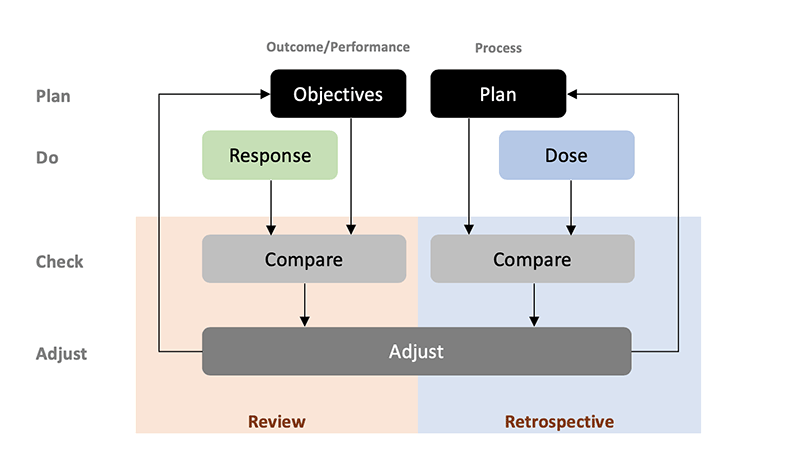
Figure 6.23. Review and Retrospective are complementary aspects of “inspect and adapt” or check and adjust components of the Deming’s cycle. Review is mostly concerned with demonstrable performance or response, while Retrospective tries to understand the underlying process.
Review and Retrospective are like fractals: self repeating iterative process that is self-similar at all scales. Figure 6.24 depicts involvement of these two inspect and adapt components an all levels of strength training and planning.
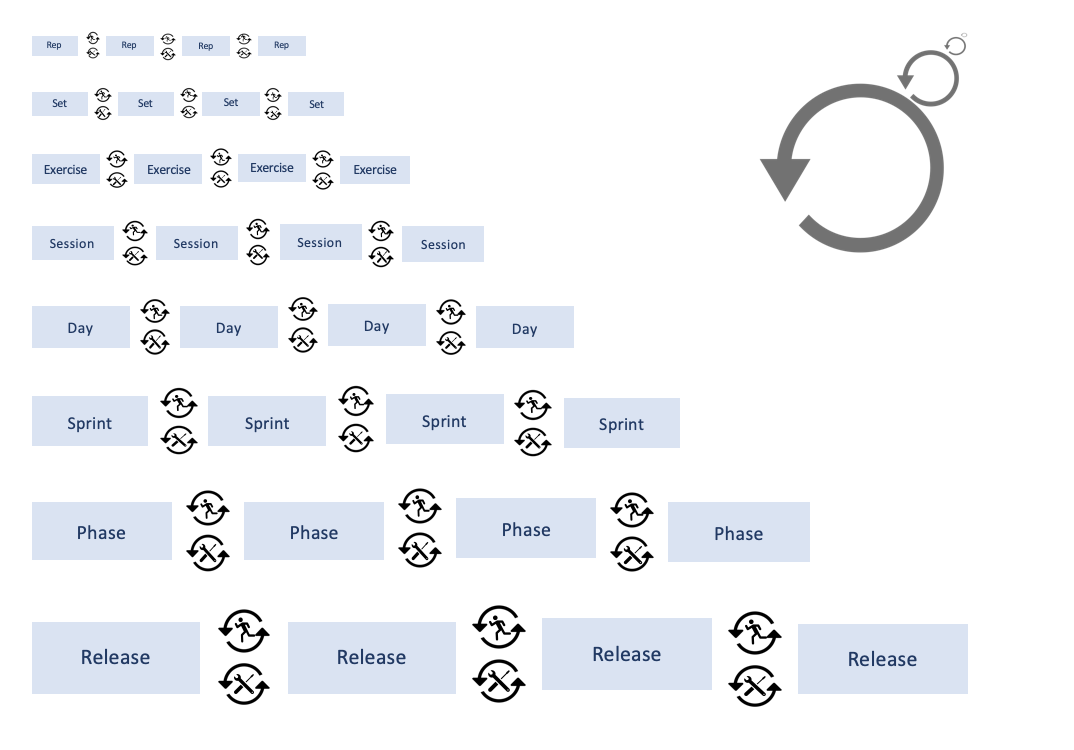
Figure 6.24. Fractal-like nature of the Review and Retrospective
This concept has already been introduced in Chapter 5 (Figure 5.20) and it is highly related to the concept of Bias-Variance tradeoff introduced in this chapter. If the program is too responsive and we adjust sprint and phase based on a single set, exercise or a day, we will introduce too much variance into the program and probably jump to noise. There is nothing wrong with inspecting and adapting at small levels, au contraire it is beneficial to take into account day-to-day variation in the current state or the errors in our long term models, but jumping levels is what is erroneous. By this I refer to changing bigger scale of the program based on review and retrospective of a single rep, set, workout. I have already discussed the point that program needs to be a bit biased (hell, all our prior knowledge introduce bias in the model or program as we always start with some prior beliefs). If we have planned intensive lower body session today, I am not that easily changing that to extensive upper body based on that morning HRV, wellness score or grip strength fluctuations (unless I see a longer term pattern, which is exactly the point of Review and Retrospective happening and affecting different time scales). These will be of course adjusted, otherwise the bias of the program would be too strong/big. If we do not make any adjustments whatsoever in the program, then the variance is very low and the program is highly biased. Nothing wrong with that, although we need to use it with caution (see Push the ceiling versus Pull the floor concept). As with the predictive models explained, training program needs to have a balance between bias and variance.
What follows is the discussion of Review and Retrospective components at different scales. The most important Review and Retrospective are at the Phase and Release levels, but it bears mentioning the others as well.
Review and Retrospective at the Repetition Level
Figure 6.25 depicts conceptual Review and Retrospective that happens between each repetition. As outlined in Chapter 5 (e.g., see Figure 5.7) feedback consists of combination of objective, subjective, internal and external sources. This might mean that one can use augmented feedback, such as linear-position transducer to estimate repetition peak velocity, mean velocity, power and you name it, or rely on coach feedback or personal rating of effort, exertion, RIR, pleasure/displeasure and so forth. This is then compared with planned and expected performance and corrective measures are being taken (see Figure 6.23 and Figure 6.25). Damn, even a simple counting can be considered Review and Retrospective (“1…2…3… two to go… tighten up… let’s go… 4…. one more… aaaand 5!”).
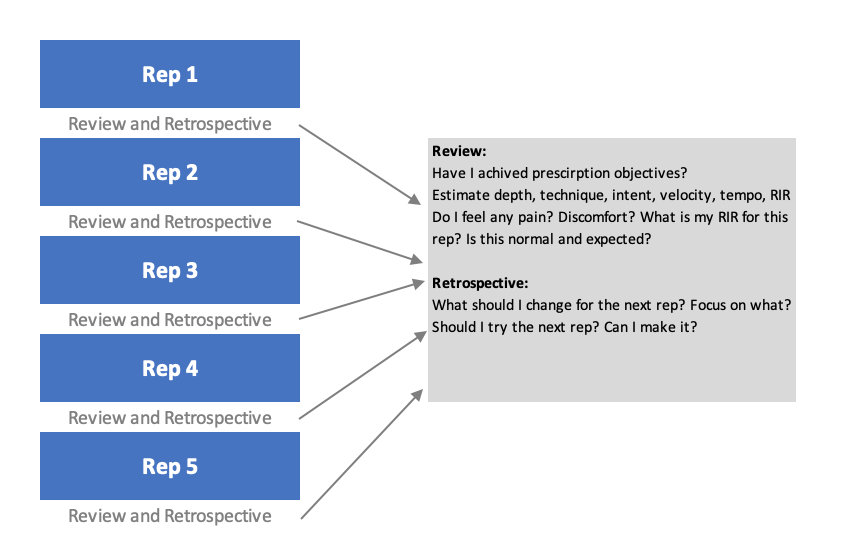
Figure 6.25. Review and Retrospective is involved after each rep
Without going into the motor learning and control discussion, it seems that external cuing and focus (not to be confused with external source of the feedback which I’ve used to classify to external and internal dose and current state estimates), outperforms internal cuing and focus (Davids, Button & Bennett, 2008). External in this case would be focusing on effects of one’s action, rather than how the body moves or feels (which would be internal). For example, “Keep your knees out” would be internal focus feedback, while “Sit on this bench and stretch the band” would be external. There are other nuances of feedback which I do not want to get into here, e.g., delayed or immediate feedback, summarized feedback, positive and negative and so forth. But it might be worth mentioning again the discussion from the Chapter 5 regarding velocity feedback, particularly for the ballistic movements. It seems that providing immediate external feedback (e.g., velocity or power, or height) during the ballistic movements, increases both the acute performance as well as chronic adaptation (Randell et al., 2011a,b; Jovanovic & Flanagan, 2014). This can also be particularly useful when performing isoPush (isometric contraction against immovable object, e.g., isometric mid thigh pull or IMTP), but in this case providing live feedback using force produced1. This external feedback can be expanded to the use of boxes or touch-bands when squatting (to make sure one squats at certain depth), putting cones on low back to make sure someone doesn’t twist when doing crawling exercises or bird-dogs, having a hanging target when performing depth jumps and so forth.
There have been a few implementations of the use of EMG devices, as a form of biofeedback2 to activate or deactivate particular muscles. For example, one might use EMG on the gluteal muscles, quads and hamstrings during the hip thrust exercise to make sure to engage the glutes, while minimizing the work of quads and hamstrings. Some physio-therapists use aneroid sphygmomanometer3 (damn, I sound smart) during some Vanilla training exercises. For example, putting the cuff under the low back (in the prone position) and doing single leg flexion without increasing the low back pressure. In this case this might be used to avoid firing up the global stabilizers and focusing on local stabilizers (or whatever the current hot theory in rehab is popular today).
The point is that Review and Retrospective is very much alive at this scale, be it external, internal, subjective or objective.
Review and Retrospective at the Set Level
Figure 6.26 depicts conceptual Review and Retrospective that happens between each set.
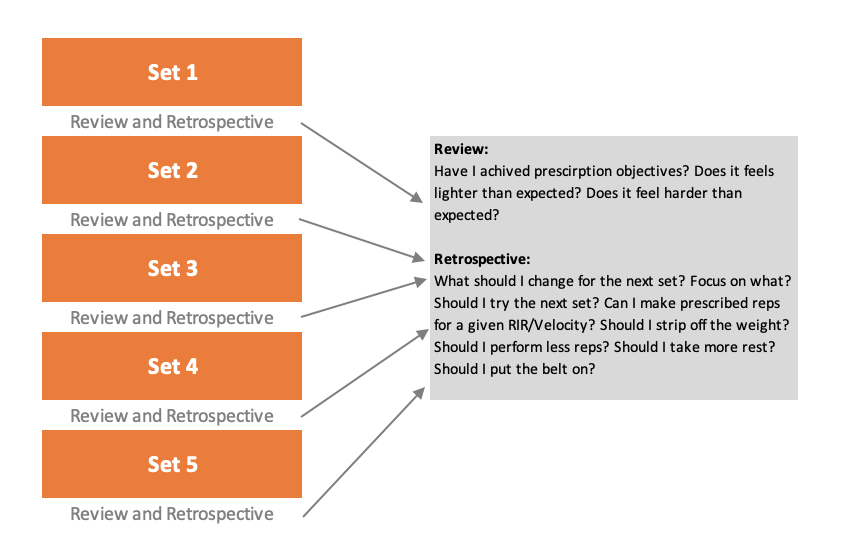
Figure 6.26. Review and Retrospective is involved after each set
Same as with the repetition level, prescription (strict or flexible) can represent a prior that needs to be updated with the current observations. Thus, Review and Retrospective also represents Bayesian updating loop (see Chapter 1). Stricter prescription would be more biased, while looser prescription would have more variance. Similar to statistical models, the goal is to find a balance between the two. This balance is believed to be achieved with individualization.
Interlude: On Individualization
In one ideological sense, individualization is about creating “equal playing field”, or making sure everyone is training at similar individual potential. What does “equal playing field” means here?
Imagine we have N=15 athletes, with a range of 85 – 110kg 1RM in the bench press. The average of this group is around 100kg (SD = 7.5kg). The first method of equality (or creating equal playing field) would be to make everyone lift 3×5 with 80kg over few weeks. The external load is equal for every individual (since everyone is lifting 80kg for 3 sets of 5), but is the internal load and hence stimuli the same for everyone? 3×5 with 80kg might be too much for some individuals and too little for others.
So we decide to use relative intensity, where load is selected based on individual 1RM. The second method uses percentages of 1RM to prescribe, e.g., 3×5 @80%. This is much better because we take into account individual differences (or individual potential). Since everyone is lifting relative to their 1RM, have we achieved equal playing field? Hold your horses my liberal social justice warrior friend. Although much improved in making things more equal, 80% of 1RM might still be too much for an individual to do for 5 reps with, or it might be too little. One solution could be to create individualized rep-max tables (which might be a pipe dream if we use many exercises, particularly with strength generalists). Other solution would be to allow for some flexibility in prescription by introducing variance in the system by giving some rep or load ranges (e.g., 3×4-6 @75-85%). Perfect? Not really, but much better.
Even with flexible prescription, few individuals might experience the set as very unpleasant, since they might be very tall, or prefer smaller number of reps in a set. So to make the equal playing field even more equal, we decide to use method number three which is even more individualized by prescribing using RIR (e.g., 3×5 w/2RIR or 3×80% w/2RIR)4. We do this since we believe that individual subjective feeling is the construct that needs to be targeted with equality. Since everyone is training at the equal potential (potential in this case being same RIR at same reps or %1RM), we must be creating same stimuli (dose) and hence we can expect same response? Sorry to disappoint, but no.
The above equality methods are mostly related to the repetition level (or a single set), but what is someone needs to do more or fewer sets? Everything else being equal, one needs 5 sets and another needs only 2 sets. So, the SJW in us sets another equality normalization level. We might measure fatigue accumulation construct across sets, with some proxy metrics, like increase in RIR rating (e.g., first set 8RIR, second 8RIR, third 9RIR, done), drop in reps at the same RIR rating (first set 5 reps @8RIR, second set 5 reps @8RIR, third set 4 reps @8RIR, done), drop in average set velocity and so forth. These are usually called Fatigue Percents (Tuchscherer, 2008, 2016), and will be explained after this interlude. So now, besides equalizing individual sets, we also equalize multiple sets. This is done by performing sets until reaching a particular metric with the aim of individualizing training dose. For example, repeating sets of 5 w/2RIR until reaching 5% fatigue level. This way we assume that everyone is training at an equal individual potential by autoregulating dose based on stress (i.e., fatigue experienced).
Figure 6.27 depicts the above methods with hypothetical Pre and Post scores.
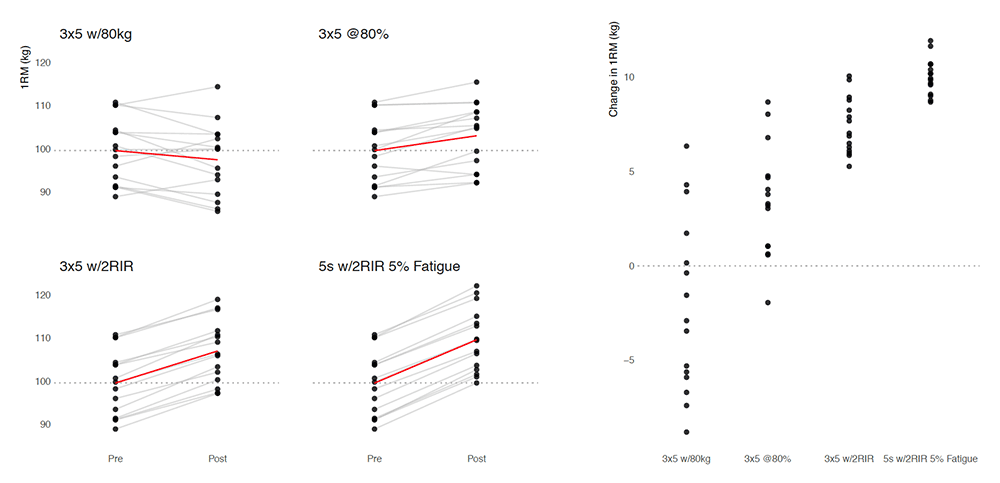
Figure 6.27. Hypothetical methods of individualizing by creating equal playing field. Each dot represents one athlete’s bench press 1RM. Left panel depicts Pre and Post score, while the right panel depict the change score (Post – Pre).
Our belief here is that by individualizing the training, we create equal playing field and hence we get higher training effects and also lower inter-individual differences in response. Figures 6.28 and 6.29 depicts this theoretical idea.
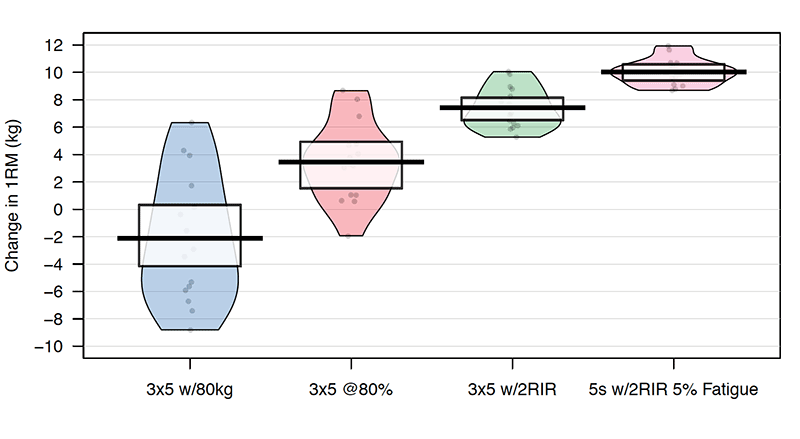
Figure 6.28. Depicting hypothetical change scores (Post – Pre) when using different methods of individualization. In theory, by individualizing the effects should be better, and inter-individual variation should be smaller.
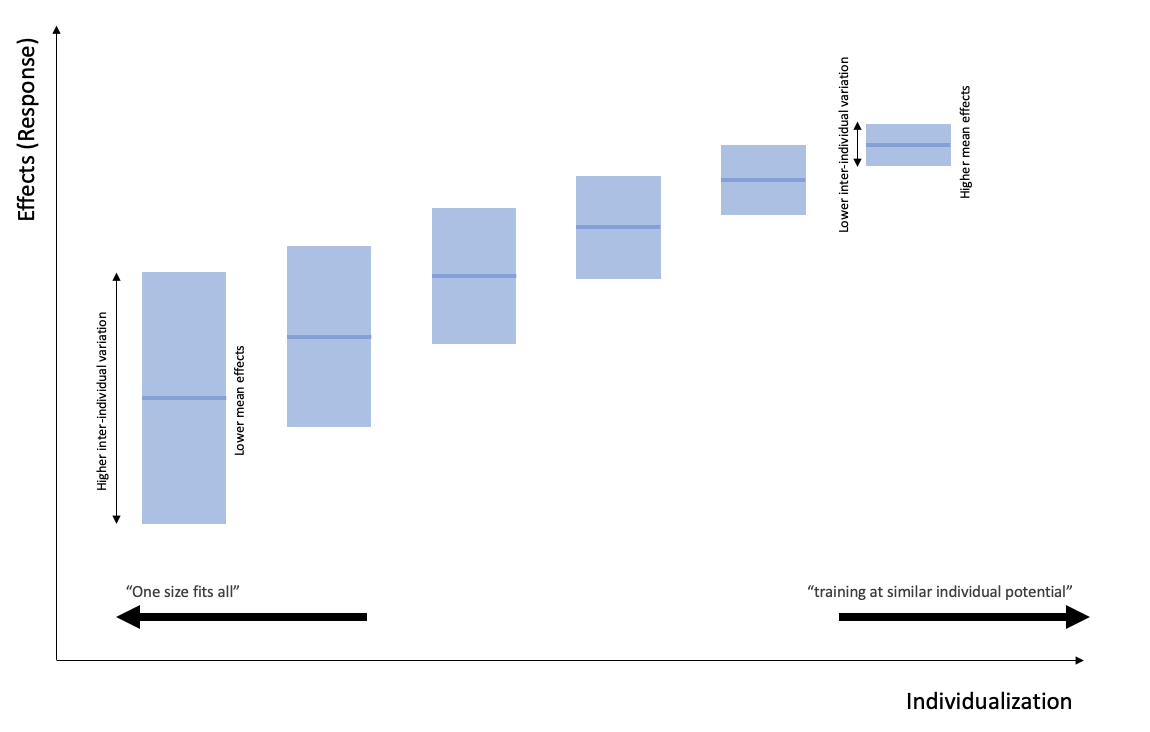
Figure 6.29. In theory, individualizing more improves the overall effect, and reduces the inter-individual variation. In theory…
This is great in theory, same as with other left wing and progressive ideas, but fails in practice. Why is that? First, there are unlimited number of variables that one can use as proxies to equalize or create equal playing field. In all methods above, we used individualization principle. We can also continue by individualizing rest time, range of motion, exercise selection, you name it. We can also use different metrics to represent those constructs (e.g. stress created by sets can be measured by drop in average velocity, increasing in RIR ratings, increase in ammonia production, drop in EMG just to name a few). Hence, it is impossible to create equal playing field, since equality can be represented with unlimited number of variables that need equalization, and by balancing one, we create havoc somewhere else. Very much similar to progressive ideologues and SJW types. But even more importantly, how the hell do we know that we have maximized individual response by equalizing individual dose metrics? What if doing “5s at 2RIR until 5% Fatigue” is epitome of self-regulating dose and creating equal playing field, but one slacks? Or one needs higher levels of dose than that equalized to progress? What if someone prefers something else? What if that same workout creates bigger soreness for few athletes, which affects the next session? What if someone suffers from fuckarounditis and needs a whip every now and then? What if we cannot manage workout like that in the group setting due facility and equipment limitation? Why do we think that dose created by “5s at 2RIR until 5% Fatigue” is actually equal to everyone? Or it will create similar responses? Why do we actually want similar responses in the first place?
The point is that we do need to strive for individualization, but keepin’ it real and understand there are numerous assumptions in the equalization process and models. We do need some bias in the program and understand that at the end of the day, even with individualization, we are still experimenting. If we get back to Figure 1.1, the aim of individualization is in forum for action, particularly with the group settings, by making sure everyone survives the workout and performs at similar individual potential or current ability. At the end of the day, we are still wrestling with uncertainty. This is about satisficing (good enough) individualization, rather than ideological or place-of-things individualization.
Rather than utilizing SJW definition of individualization, I prefer another one (see Figure 6.30). It is not about training at equal individual potential, as much it is about reaching full (or better yet, satisficing) potential while avoiding the downsides. Surely, making sure that one is not killed in the workout by using dose individualization is a step forward, but it is not the end goal. Most likely, there is a tipping point where this equal playing field becomes detrimental or exercise in futility.

Figure 6.30. Better definition of individualization.
Back to the Set Level
Besides individualization by utilizing relative prescription in trying to match athlete’s current ability (stable level of adaptation and current state), Review and Retrospective also deals in making sure that what is actually prescribed is being realized. For example, if a hard workout is planned, one wants to make sure hard workout is actually done. This doesn’t mean following a program to the letter, but acknowledging program constraints and bias, while providing for some variance to take into account errors in the prescription and current ability of the athletes.
For example, if program calls for 80% 1RM, one way to make sure that actually 80% is used is to either use predicted or estimated 1RM (done with LV profile or using RIR equation), VBT prescription by using velocity associated with 80% 1RM from the individual LV profile (e.g., 80% 1RM is around 0.7 m/s5, or daily nRM6. Then the training percentages can be based off that current performance rather than pre-phase 1RMs7.
Do whatever is prescribed as main prescription (e.g., 3×5 @80%)
or
Do whatever is prescribed as main prescription (e.g., 3×5 @80%)
Some lab coats believe that using nRMs and training to failure is the only way to make sure one is creating equal playing field within treatment groups9. I would say that could be an option, but then the study will lose ecological validity, since the design doesn’t represent how prescription, programming and training happens in the wild. This “evidence-based” stuff is not that clear cut after all. We create artificial equal playing field in the lab with the hope of minimizing confounders and getting clearer causal inference, but then that inference is useless in the wild since no one bloody trains that way.
The use of RIR to prescribe is also about making sure that the individual exertion is actually being met. But that’s easier on single set level. When it comes to multiple sets, how do we know what is enough? One way would be to follow prescribed prior (e.g., 3 sets) and another would be to auto-regulate number of sets by some criteria. For example, if we planned 5 sets of 5 at 80% w/2RIR and the following pattern starts to happen:
Set 2: 5 reps with 100kg (80%) w/1RIR
Set 3: 5 reps with 100kg (80%) w/0RIR
What should we do? Should the training stop? Should we have modified the prescription at set 3? How should we continue this workout? This also depends on what program are we running – is it “push the ceiling” under which we try more to force the athlete to the program, or “pull the floor” under which we would adapt to the athlete and call it a day10?
Fatigue Percentages
Mike Tuchscherer (Tuchscherer, 2008, 2016) provided a simple way to auto-regulate11 volume using RPE or RIR. So rather than prescribing total number of sets (although I would still be prescribing expected number or range), one can prescribe Fatigue Percentages as a quality threshold. As already explained in the interlude on individualization, we believe that by utilizing this type of individualization we create equal playing field (e.g., everyone is training at similar stress or fatigue level), but more importantly we believe that this prescription will yield better outcomes by reaching athletes’ full/satisficing potential. In my opinion, the use of these auto-regulating methods depends on the type of program, whether it is of push the ceiling or pull the floor nature. But anyway, what fatigue percentages represent? Here is the quote from Mike Tuchscherer (Tuchscherer, 2016):
At the most fundamental level, a fatigue percent is simply trying to measure how tired you’ve gotten. If you’re familiar with the principles of RTS, you’re aware that it is possible to reasonably estimate a 1RM on most sets given the load, number of reps, and RPE of the set. If we watch how this estimated 1RM behaves from set to set, we can easily see when fatigue begins to creep in.
This is essentially what you do with a traditional fatigue percent anyway – you work up to the heaviest set that you will do on that day (i.e. your “initial”) and you drop the bar weight by the specified percentage. You continue to do sets with the reduced load until your reps and RPE matches that of your “initial”. Then you know you have achieved the desired level of fatigue. This is what is known as a “load drop” because it is the load on the bar that is dropped after the initial. If you were to look at the estimated 1RM’s of each lift, you’ll see that this also correlates to the desired fatigue percent. And it is this realization that allows us to do more interesting things with our post-initial sets.
Fatigue Percentage are easy to explain using an equation. We have already covered simple 1RM prediction formula:
We can calculate this est1RM for every set using RIR, weight used and number of reps. Fatigue Percentage is thus nothing more than difference ratio between initial set and the following sets:
or
Table 6.3 contains few examples of auto-regulation and calculation of the Fatigue Percentage. The “Common” example is finishing prescribed set by going to failure. Load drop method is dropping weight and continuing doing sets until initial RIR is being experienced (as explained in the Mike Tuchscherer quote above). Rep drop is maintaining weight but dropping number of reps and continuing until initial RIR is being experienced. Combination is just a combined load and rep drop.
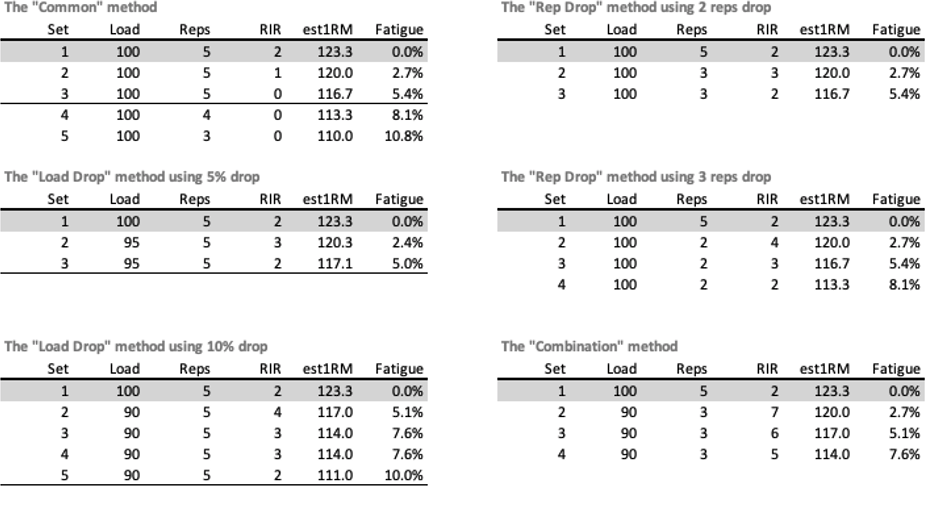
Table 6.3. Estimated Fatigue Percentage using different methods of auto-regulation.
According to Mike Tuchscherer, Fatigue Percentage can be associated with planned dose of training. Table 6.4 is modified based on the ideas by Mike Tuchscherer (Tuchscherer, 2008).
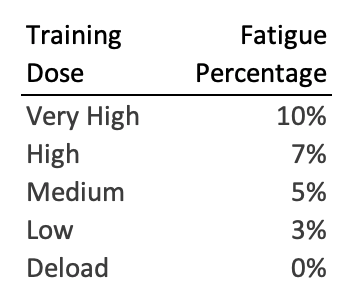
Table 6.4. Fatigue Percentage associated with qualitative dosage (Tuchscherer, 2008).
Using Fatigue Percentage with the load drop method is easy – you just need to drop the initial set weight on the bar for planned Fatigue Percentage and continue doing sets until initial RIR is being experienced (see Table 6.3 for examples). But what about rep drop? How do we know how many reps needs to be dropped for a planned Fatigue Percentage?
If we simplify the following equation for Fatigue Percentage, where N is drop in rep (or RIR) :
Fatigue Percentage = 1 – (((Weight x (Reps + RIR – N) x 0.0333) + Weight) / ((Weight x (Reps + RIR) x 0.0333) + Weight)
we will get the following equation:
Table 6.5 contains Fatigue Percentages given initial number of reps and initial RIR and planned rep drop. This is again a “Small World” model based on Epley’s equation.
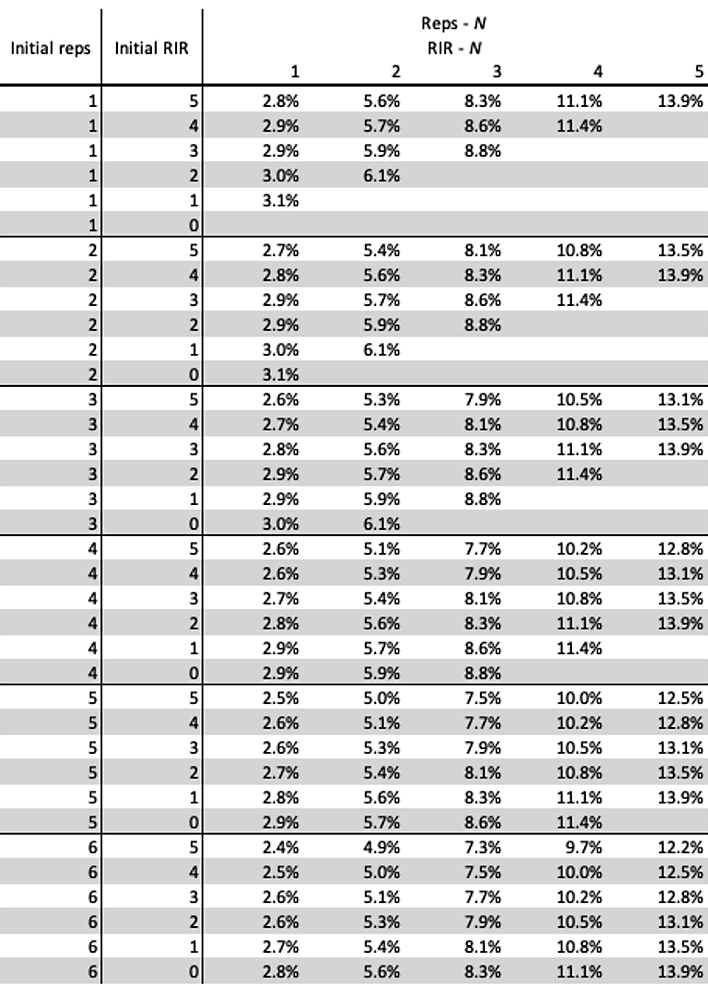
Table 6.5. Fatigue Percentages given initial number of reps and initial RIR and planned rep drop
Table 6.5. can be simplified with simple sum of initial number or reps and RIR. This modified approach is on Table 6.6
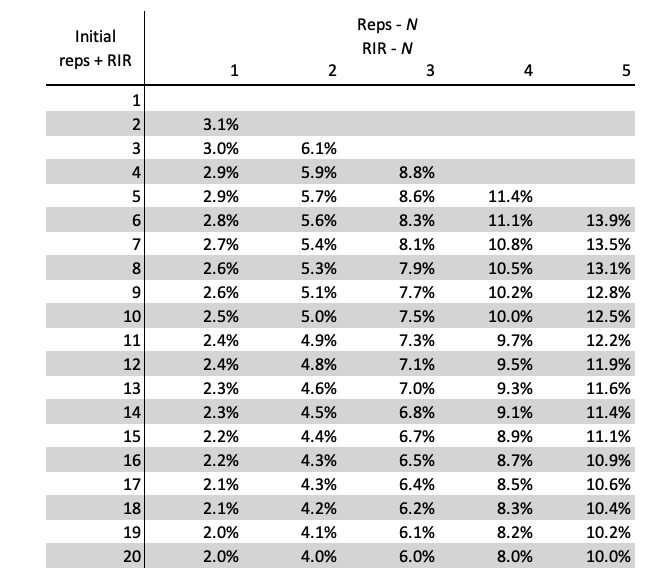
Table 6.6. To simplify table 6.5, simple sum of initial reps and RIR can be used instead
Let’s use a simple example. Suppose we planned doing sets of 5 with 2RIR for 5% Fatigue using rep drop method. The initial sum of reps and RIR is equal to 7 (5 + 2) and planned Fatigue Percentage is 5%. We just find rep drop from Table 6.6, which is around 2 reps. So our workout looks like this:






Responses