Validity and Repeatability of the YoYoIR1 and 1000TT: Re-analysis of the Clancy et al. paper
In the following two videos and a PDF report I am going to re-analyze the paper by Clancy et al. (LINK) using bootstrap magnitude-based approach (using bmbstats package) and mixed-effects model in R language. The purpose of these videos is educational, probably more to me than to people watching. If you spot any inconsistencies or want to provide any input, please be free to do so below in the comments.
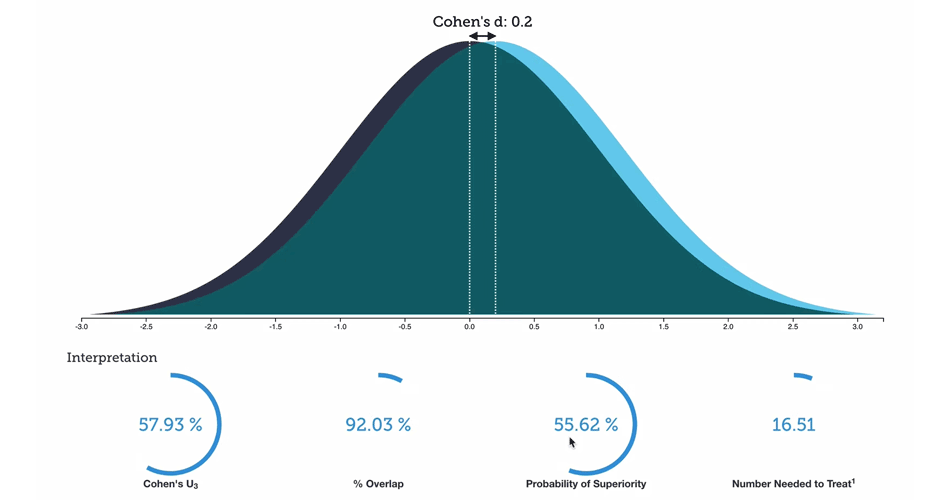
Paper by Clancy et al. is quite interesting since it provides an attempt at answering one question that I keep getting often: “Can we predict MAS from YoYoIR1 scores?”. Not sure this design and my analysis provide a direct answer (since I think that 1000m time-trial overestimates MAS), but I am pretty confident it brings more “fuel to the fire”.
In the first video, I am going through the “predictive” perspective of the validity analysis using the magnitude-based approach and how the conclusions can differ based on our apriori decisions. For more information about the bmbstats package, please read the of the book or order paperback on Amazon. One handy thing I am explaining in this video is the SIMEX procedure (hoping to see this more in sport science research).
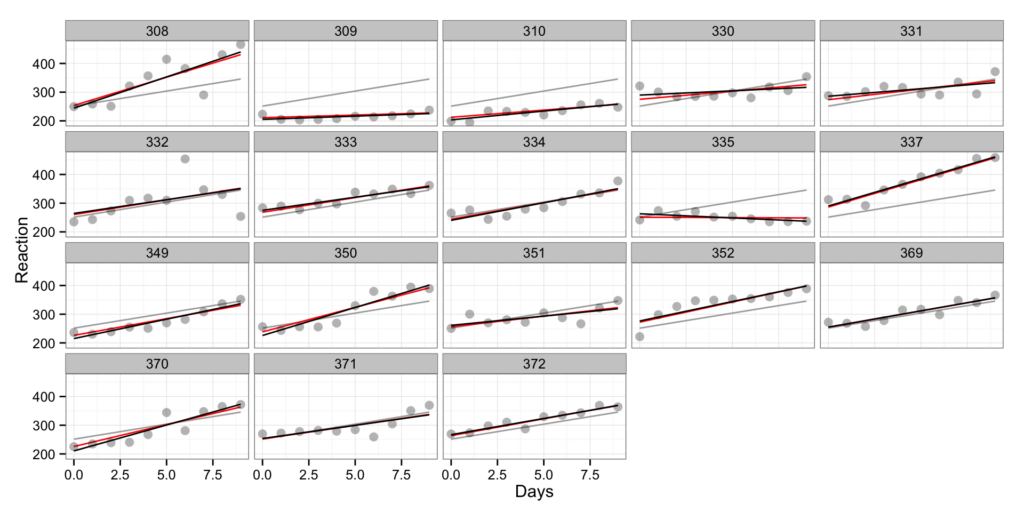
In the second video, I am going through a simple simulation to understand the effect of the true data-generating-process (DGP) on the model estimate of random error. Here I will review the method of the differences, simple linear regression, ordinary least products (OLP) regression, individual regression models (for more than 2 trials), random intercept model, random slope and intercept model, and random intercept model with the nominal trial predictor.
In the files you can also find the mm-report.pdf that provides a summary of the simulations, but also uses the first and last trial for the estimation of the random error. In that file, you can easily see the failings of certain models.
Download all the files here: Download






Responses