Mladenverse: Collection of R Packages
2020 was a tough year for many. I took the lockdown as an opportunity to finish some old projects, start new ones, and learn new skills. The tipping point happened when I’ve read two of Hadley’s Wickham (who, funny enough, blocked me on Twitter, probably due to my calling out of leftist ideologies within R community; I still have huge respect for his work) books on the R-language, as well as book on R Markdown extension called bookdown:
- Advanced R. Paperback. Website
- R Packages. Paperback. Website
- bookdown: Authoring Books and Technical Documents with R Markdown. Paperback. Website
These gave me the new skills, and confidence to close some long-lasting projects (yes, vjsim and bmbstats I am looking at you two). All in all, I ended up writing 7 R-language packages (see figure below), with one being published on CRAN (shorts). I will take the opportunity to introduce each package from this Mladenverse and announce some developments that I plan to do. All of these packages are open-source and aim to solve or help to solve problems that we, strength coaches and sports scientists, are facing regularly.
bmbstats: Bootstrap Magnitude-based Statistics
In 2018, I have collected the data for my PhD project, together with Ivan Jukić(who is now at SPRINZ in New Zealand) in Zagreb, Croatia. Being a contrarian, I couldn’t accept the simple, and useless for practice, frequentist analysis of the data (as well as now critiqued MBI, since it didn’t answer practice questions that I was curious about). So I started experimenting, particularly with bootstrap. When I did the initial analysis of the data, I was at Jorge Canales’s apartment for almost a month in Buenos Aires, Argentina. It was shitty weather (raining like hell, and I managed to screw-up my back in the gym), I waited to get back to Serbia to buy my first motorcycle (Kawasaki Vulcan S, but now I ride Africa Twin Adventure Sports, and, of course, I am contemplating about the new KTM 890 Adventure R). In short, I ate dulce de leche, steaks, and work on the data analysis.
I finished some initial R functions to do the analysis, but I wasn’t happy with it. The whole project got postponed. Ivan Jukic and I were back and forth with this, but it was me who was screwing around trying to implement something novel. I was also working on HIT Builder and writing HIIT Manual.
In the meantime, I took the time to read about stats as much as possible and even tried to rewrite the analysis functions multiple times. A year later, in 2019, while I was writing the Strength Training Manual, I also started working on a preprint trying to outline my magnitude-based reasoning and the use of bootstrap when analyzing the data. That preprint is available at SportRxiv repository: https://osf.io/preprints/sportrxiv/dnq3m/. I was also flerting with evaluating robustness of planning for my Agile Periodization project (see another preprint here: https://osf.io/preprints/sportrxiv/8n4jf/). All in all, I was everywhere, swamped with various projects and interests.
Lorena Torres and Duncan French approached me with the project of writing a chapter for NSCA, which will be published in February 2021 (NSCA’s Essentials of Sport Science). I already had the preprint, so we decided to use it and modify it (i.e., butcher it down, since I am famous for writing damn long articles) to become the chapter in the book.
I started reading the before-mentioned books and was rewriting both the paper/chapter and the package multiple times. And finally nailed it – resulting in a bmbstats package, but also an open-source full-length book, which I finished in the Summer, 2020. I decided to write a book myself (just a few months after publishing the Strength Training Manual), since a short chapter in the NSCA book didn’t serve me justice in expressing and explaining the tool (i.e., bmbstats package).

bmbstats package: https://mladenjovanovic.github.io/bmbstats/
bmbstats book: https://mladenjovanovic.github.io/bmbstats-book/
Both the book and the package are free, open-source projects. The paperback version of the bmbstats book, available through Amazon (both for Kindle and paperback) cost some dollars because it was printed in color. And I always like having a proper, physical book in my hands rather than reading PDF on the iPad.

I am currently reading Andrew Gelman’s Regression and Other Stories (which is a must-read) as well as another book on Bayesian analysis and stats in general, so I plan to revisit the bmbstats book in the near future (i.e., maybe by adding few more chapters and revisiting the material one more time). Another project I have in mind, particularly when I nail the mixed-models a bit better, is to create a case-studies book, that will collect various, pedagogically organized, cases and provide analysis/solutions from various colleagues and commentary by the editor. This way, we can learn/teach statistics and analysis from the ground-up, rather than from the top-down. This can also serve as a handbook. If you are interested in helping with such a project, do not hesitate to contact me through email.
Ivan Jukić and I also managed to publish the first paper from my PhD project using the bmbstats package and provided the few novel estimators that answer more practical questions by the coaches.
Paper: https://pubmed.ncbi.nlm.nih.gov/33044368/
Data repository: https://osf.io/sxrju/
Ivan Jukić should be creating one or more instructional videos on our paper and analysis implemented, hopefully soon. The guy is busy as hell.
vjsim: Vertical Jump Simulator
I think I started working on vjsim in late 2017 since I couldn’t understand and grasp Samozino and JB-Morin’s optimization models. I ended up creating a Shiny simulator and dashboard, but I wasn’t really happy with it. It took me two years to finish it. What gave me the strength, but more importantly the skillset, was the above-mentioned books. I decided that this project needs better packaging and documentation, particularly the theoretical model of the vertical jump that I have implemented in the simulation. That is how vjsim was born. The documentation (i.e., package vignettes; e.g., start HERE) were extensive and great intro to biomechanics of the squat jump. Few professors were using both the documentation and the Shiny simulator to provide their students with additional material for the biomechanics classes.

Website: https://mladenjovanovic.github.io/vjsim/
Simulator: https://athletess.shinyapps.io/shiny-simulator/
Course: https://complementarytraining.com/courses/force-velocity-profiling-and-training-optimization-course/
vjsim not only contains the simulator functions but also practical functions to analyze your own data. During lockdown here in Serbia, I decided to actually create a practical Force-Velocity Profiling video course to showcase the theoretical models behind the squat jump, but also how to use vjsim to analyze your own data. This was really helpful since all analyses using Samozino’s model were implemented in MS Excel. But now with the vjsim, the analysis and visualization can be done for multiple athletes without fuss.
shorts: Short Sprints
Early 2020, I got approached by Jason Vescovi, since I was posting some stuff on sprint profiling on the Twitter (if memory serves me well, I think I was discussing a paper by Ken Clark et al.). Jason had some sprint testing data to be analyzed and I had a few ideas. To avoid HARK-ing (hypothesizing after results are known), we decided that Jason sent me a random sample of his data so I can explore and try to fit different models and test different hypotheses. Once we have a defined analysis, we will run it on the full data-set.
The R code for the analysis that I wrote could definitely be re-usable, so I decided to create an R package: shorts. shorts is short of Short Sprints and it is the only package (until this point) that is available at CRAN.

Website: https://mladenjovanovic.github.io/shorts/
CRAN: https://cran.r-project.org/package=shorts
Through multiple iterations, I have expanded the package to include mixed-models, force-velocity profile, and most importantly novel model corrections for the flying sprint issues (i.e., someone starting behind the initial timing gate, or cutting the timing beam prematurely, etc).
The vignette inside the package attempts to explain these issues with the short sprints modeling, and it can be accessed at the website.
Jason Vescovi and I have submitted two papers using the shorts package and they are currently under review. One paper, which is more technical and deals with all the functionalities of the shorts package is available as the preprint (below). This paper is submitted to the Journal of Statistical Software.
Preprint: Jovanovic, M., & Vescovi, J. D. (2020, November 30). shorts: An R Package for Modeling Short Sprints. https://doi.org/10.31236/osf.io/4jw62
Here is our conclusion from the paper:
We are hoping that the shorts package will help fellow sports scientists and coaches in exploring short sprint profiles and help in driving research, particularly in devising measuring protocols that are sensitive enough to capture training intervention changes, but also robust enough to take into account potential sprint initiation and timing inconsistencies.
dorem: DOse-REsponse Modeling
One of the best and the most practical papers I have read is Clarke & Skiba’s “Rationale and resources for teaching the mathematical modeling of athletic training and performance” (DOI: 10.1152/advan.00078.2011). Ever since reading that paper, I was interested in Banister’s Impulse-Response (IR) model and even wrote few R scripts myself (LINK, LINK).
In early 2020, Sean Williams and Eva Piatrikova asked me to co-author a paper with them on HRV monitoring and we have used my R code to fit the Banister models. This paper is now in press:
Piatrikova, E., Willsmer, N., Altini, M., Jovanovic, M., Mitchell, L., Gonzalez, J., Sousa, A., & Williams, S. (Accepted/In press). Monitoring the heart rate variability responses to training loads in competitive swimmers using a smartphone application and the Banister Impulse-Response model. International Journal of Sports Physiology and Performance.
Since 2019, I have been exchanging emails with Ben Stephens Hemingway who is researching mathematical IR models and we have been talking about developing an easy-to-use R package to help fellow researchers implement various IR models. Back then, I didn’t have the necessary skills to do so, but once learning to make R packages and learning about the hardhat package I was able to create dorem package (short of DOse REsponse Model). Hardhat is an outstanding package that aims to help developers create new model packages:
hardhat is a developer-focused package designed to ease the creation of new modeling packages, while simultaneously promoting good R modeling package standards as laid out by the set of opinionated Conventions for R Modeling Packages.
This allowed me to create a very neat and easy to use implementation of not only Banister IR but also rolling average and exponential rolling average models.
Website: https://dorem.net/
dorem also implements cross-validation and random shuffling of the predictors to test model overfit and sensitivity. My goal with dorem in the near future is to expand it to involve classification models (although it is already possible to implement it using the link function) which can be used with injury prediction models, but more importantly mixed-models to allow N>1 models (since IR models are built for N=1 or individual athletes) and estimation of the posterior probabilities of model parameters (now dorem uses optimization models that provide a single solution, but maybe in the near future I can try to implement it Stan language, but I still do not have the knowledge to do so).
Together with Ben Stephens Hemingway, Paul Swinton, and Leon Greig, we are trying to develop these features. We have also submitted one review paper on the topic which is available in the preprint:
Stephens Hemingway, B., Greig, L., Jovanovic, M., & Swinton, P. (2020, September 17). A narrative review of mathematical fitness-fatigue modeling for applications in exercise science: Model dynamics, methods, limitations, and future recommendations. https://doi.org/10.31236/osf.io/ap75j
dorem package implements modular approach, which allows for easier extension of the package. I will use this opportunity to call developers to contribute to this project and help develop a powerful tool for fellow researchers and sports scientists.
athletemonitoring
Athletemonitoring package started as my attempt to create an easy way to aggregate, analyze, and visualize training monitoring data from the AthleteSR. Since I had to create a way to easily analyze monitoring data without a priori knowledge about it, I had to write more universal/general functions. And as such, they could be used across various scenarios. These involve dealing with missing entries, missing days (or levels of analysis), aggregating data (i.e., multiple sessions in a single day), rolling functions, and comparing individual vs. group trends.

Website: https://mladenjovanovic.github.io/athletemonitoring/
Outlining this universality finally resulted in the Athlete Monitoring Course, that is currently going on at the site.
I am hoping that this package will help researchers and sports scientists perform the common data aggregation (e.g., acute and chronic rolling averages) that allow easy reproducibility, particularly for the research.
STM: Strength Training Manual
This small package is the result of my attempt to get ready to work on the Strength Training Manual Volume 3 and help me generate tables and graphs more easily. If there is something that I have learned over the last few years and three books behind me, is the following: When embarking on the unknown voyage (e.g., book writing, since that is not a simple mental dump, but active exploration and a lot of dead ends along the way which readers do not see), first build or get tools . The Strength Training Manual features more than 200 tables and more than 1,500 set and rep schemes. If I had to generate these manually, I would be still writing them.

Website: https://mladenjovanovic.github.io/STM/
If you are interested in generating your own set and rep schemes easily, learning basic STM commands will be o huge help.
VBTsim
As I have already alluded, my PhD topic is Velocity-Based Training (VBT) and Ivan Jukić and myself already published one paper of the few.
In my own research and implementation of the VBT, I have noticed a lack of a theoretical model. Yes, there are numerous papers on the VBT, but NONE provides a theoretical model, but only statistical models. Yes, there are plenty of papers dealing with reliability and stuff, but none outlining theoretical underpinnings.
I have been reading the following papers on theory building and formal models in psychology and noticed the same issues with VBT:
- Borsboom, D, van der Maas, H, Dalege, J, Kievit, R, and Haig, B. Theory Construction Methodology: A practical framework for theory formation in psychology. PsyArXiv, 2020 cited 2021 Jan 11.Available from: https://osf.io/w5tp8
- Fried, EI. Lack of theory building and testing impedes progress in the factor and network literature. PsyArXiv, 2020 cited 2020 Nov 24.Available from: https://osf.io/zg84s
- Fried, EI. Theories and models: What they are, what they are for, and what they are about. PsyArXiv, 2020 cited 2020 Nov 24.Available from: https://osf.io/dt6ev
- Smaldino, PE. Models Are Stupid, and We Need More of Them. In: Computational Social Psychology. Vallacher, RR, Read, SJ, and Nowak, A, eds. . New York : Routledge, 2017. | Series: Frontiers of social psychology: Routledge, 2017 cited 2021 Jan 11. pp. 311–331. Available from: https://www.taylorfrancis.com/books/9781351701686/chapters/10.4324/9781315173726-14
Here is a great summary from Smaldino’s chapter:
Humans, scientists included, are limited beings who are bad at forming intuitions about the organization and behavior of complex systems. Verbal models, while critical first steps in scientific reasoning, are necessarily imprecise. Overreliance on verbal models can impede precision and, by extension, impede progress in our understanding of complex systems. Formal models are explicit in the assumptions they make about how the parts of the system work and interact, and moreover are explicit in the aspects of reality they omit. This has the potential disadvantage of making formal models appear stupid. And of course, they are stupid, because we are limited beings and stupid models are the best we can do. As Braitenberg writes, fiction will always be part of science “as long as our brains are only minuscule fragments of the universe, much too small to hold all the facts of the world but not too idle to speculate about them” (Braitenberg, 1984, p. 1). An old adage holds that it is better to stay silent and be thought a fool than to speak and remove all doubt. As scientists, our goal is not to save face, but in fact to remove as much doubt as possible. Formal models make their assumptions explicit, and in doing so, we risk exposing our foolishness to the world. This appears to be the price of seeking knowledge. Models are stupid, but perhaps they can help us to become smarter. We need more of them.
VBTsim is very similar to vjsim in the way that it provides a formal VBT model that allows data simulation, but also analysis of observed data. I am currently developing this package as well as writing a paper to outline the VBT formal/theoretical model and VBTsim functionalities. In addition to this, I have created a Shiny dashboard (similar to what I have done with vjsim ) to provide a very simple and intuitive guide and exploratory tool. I am still keeping this “under the radar” and the website is still not public yet.
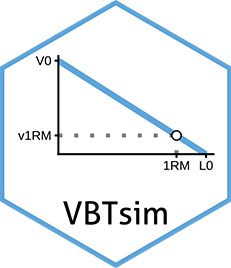
Website (soon to be public): https://mladenjovanovic.github.io/VBTsim/
One of my main concerns with VBT research, besides the lack of theoretical underpinnings, is the reliance on (practically) useless statistical estimators (i.e., R^2, p-values). I am working on a novel set of estimators that aim to quantify prescription error (both given the model, and observed data). Prescription error estimators aim to answer more practical questions that coaches might have (i.e., “If I implement this method of prescription, how much I will be off and will I be better off than using other methods?” and “With whom I can use VBT prescription, and with whom I might expect useless prescription”).
I am hoping to write two papers using VBTsim, one outlining theoretical model and simulations, and one that validates the model with the data that I have collected. I will probably create a practical course on VBT in 2021. Watch this space.
Conclusion
As an independent researcher and sports scientist, I am hoping to contribute to our field by creating open-source tools. I am still learning R development and statistics, but I hope to create many more packages in the near future. If you have any ideas or problems worth developing a package about, let me know! All in all, although generally a shitty year, 2020 was good in terms of closing a bunch of projects.







Responses