How to Make a Readiness Monitoring Using a Simple Wellness Questionnaire [Part 2]
Click here to read the first part of the article »
In this part I am going to cover how to collect the data in the Excel and how to numerically analyze it.
This involves:
- Color-coding individual categories (fatigue, sleep…)
- Color-coding total score (sum of categories)
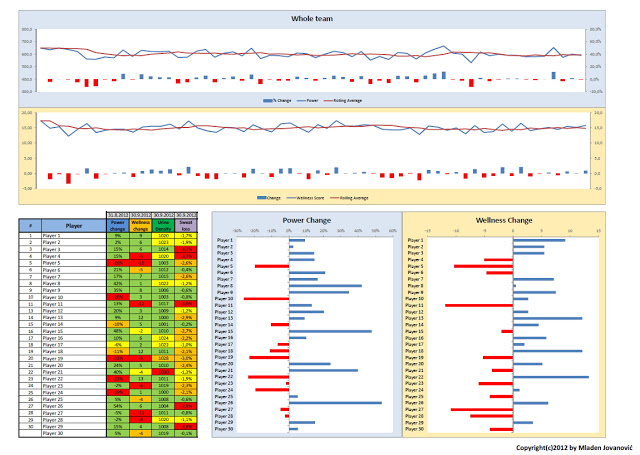
- A way for calculating base-line and trends using rolling average of the last six measurements
- How to calculate the difference of the current score to the individual tendency (which is calculated by rolling average)
Since the wellness questionnaire is basically a nominal scale, the method of calculating difference might be simple subtraction (Difference = Current Score – Rolling Average). Other calculations that are based on ratio scales might involve percent change (Difference[%] = (Current Score – Rolling Average)/ Rolling Average x 100) or Z-score (Z-Score = (Current Score – Rolling Average)/Rolling Standard Deviation) and all of these might vary on how you calculate baseline, whether it is a rolling average (what amount of measurements should be taken into account?), or just plain average of all measurements, or even an average of measurements in some period (for example pre-season).
Interesting point is that calculating the baseline allows us to deal with players who score higher-or-lower than normal, while calculating Z-scores allows us to deal with players who show higher or lower variability in their scoring.
To be clearer, we have three players who score:
| Average | SD | CV | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Athlete A | 15 | 14 | 16 | 15 | 14 | 15 | 16 | 15,0 | 0,82 | 5% | |
| Athlete B | 10 | 9 | 11 | 10 | 9 | 10 | 11 | 10,0 | 0,82 | 8% | |
| Athlete C | 15 | 13 | 17 | 15 | 13 | 15 | 17 | 15,0 | 1,63 | 11% |
Athlete A tends to always report lower scores, while Athlete B tends to always report higher scores. Calculating simple difference score (in this case score minus average) provides a method to deal with this scenario instead of relying on absolute numbers as a sign of reduced readiness.
| Difference | |||||||
|---|---|---|---|---|---|---|---|
| Athlete A | 0 | -1 | 1 | 0 | -1 | 0 | 1 |
| Athlete B | 0 | -1 | 1 | 0 | -1 | 0 | 1 |
| Athlete C | 0 | -2 | 2 | 0 | -2 | 0 | 2 |
As you can see both Athlete A and Athlete B have same difference scores compared to their average (baseline). But what about Athlete C? He is always double.
Both Athlete C and Athlete B have same average score (15), but way different difference scores. What you can judge from the example is that for each change in Athlete B’s score Athlete C scored double. Thus, Athlete C has higher variability in his scoring (see his SD and CV).
As some athletes tend to report normally higher-or-lower scores, some athletes tend to have higher-or-lower variability as well. Does this means they are automatically more or less ready to train, more or less tired? Not necessary so. I guess we need to take into account their natural variability and find a way to calculate it and take into account.
One solution would be to use Z-score:
| Z-score | |||||||
|---|---|---|---|---|---|---|---|
| Athlete A | 0,00 | -1,22 | 1,22 | 0,00 | -1,22 | 0,00 | 1,22 |
| Athlete B | 0,00 | -1,22 | 1,22 | 0,00 | -1,22 | 0,00 | 1,22 |
| Athlete C | 0,00 | -1,22 | 1,22 | 0,00 | -1,22 | 0,00 | 1,22 |
As you can see, all three athletes deviate the same from the average when we use the Z-score. Thus you see that none of them is more tired or more ready compared to whole group.
In this installment I used simple difference score (since the wellness is based on nominal scale and not ratio scale), but you can play around and implement Z-scores. In that case you would need additional tab to calculate rolling SD (standard deviation) the same way we calculated rolling averages. In that case GREEN zone might be from 0 to – 1SD, ORANGE zone from -1SD to -2SD and RED everything below -2SD.
For more info I suggest checking the following papers from JASC (thanks to Dan Baker for sending them)
Fatigue monitoring in high performance sport: A survey of current trends. J. Aust. Strength Cond. 20(1)12-23. 201
Monitoring overtraining in athletes: A brief review and practical applications for strength and conditioning coaches. J. Aust. Strength Cond. 20(2)39-51. 2012

In the next installment I will cover one simple way to visualize this for better decision making, along with designing a very simple dashboard.





Responses