How to (Pretend to) Be a Better Coach Using Bad Statistics

Here is a simple scenario from practice: Coach A uses YOYOIRL1 test and Coach B uses 30-15IFT (for more info see paper by Martin Buchheit, which also stimulated me to write this blog) to gauge improvements in endurance.
Coach A: We have improved distance covered in YOYOIRL1 test from 1750m to 2250m in four weeks. That is 500m improvement or ~28%
Coach B: We have improved velocity reached in 30-15IFT from 19km/h to 21km/h in four weeks . That is 2km/h improvement or ~10%
If you present those to someone who is not statisticaly educated he/she might conclude the following:
- Coach A did a better job, since the improvement is 28% compared to 10% of Coach B
- YOYOIRL1 test is more sensitive to changes than 30-15IFT
As a coaches, we needs to report to a manager(s), so which one would you prefer reporting? 28% or 10%? Be honest here!
Unfortunately, we cannot conclude who did a better job (Coach A or Coach B), nor which test is more sensitive (YOYOIRL1 or 30-15IFT) from percent change data. A lot of managers and coaches don’t get this. At least I haven’t until recently.
What we need is Effect Size statistics, or Cohen’s D. But for that we need to know variability in the groups, expressed as SD (standard deviation). Let’s simulate the data and use usual SDs for YOYOIRL1 and 30-15IFT
require(ggplot2, quietly = TRUE)
require(reshape2, quietly = TRUE)
require(plyr, quietly = TRUE)
require(randomNames, quietly = TRUE)
require(xtable, quietly = TRUE)
require(ggthemes, quietly = TRUE)
require(gridExtra, quietly = TRUE)
set.seed(1)
numberOfPlayers <- 150
playerNames <- randomNames(numberOfPlayers)
# Create YOYOIRL1 Pre- and Post- data using 300m as SD
YOYOIRL1.Pre <- rnorm(mean = 1750, sd = 300, n = numberOfPlayers)
YOYOIRL1.Post <- rnorm(mean = 2250, sd = 300, n = numberOfPlayers)
# We need to round YOYOIRL1 score to nearest 40m, since those are the
# increments of the scores
YOYOIRL1.Pre <- round_any(YOYOIRL1.Pre, 40)
YOYOIRL1.Post <- round_any(YOYOIRL1.Post, 40)
# Create 30-15IFT Pre- and Post- data using 1km/h as SD
v3015IFT.Pre <- rnorm(mean = 19, sd = 1, n = numberOfPlayers)
v3015IFT.Post <- rnorm(mean = 21, sd = 1, n = numberOfPlayers)
# We need to round 30-15IFT to nearest 0.5km/h, since those are the
# increments of the scores
v3015IFT.Pre <- round_any(v3015IFT.Pre, 0.5)
v3015IFT.Post <- round_any(v3015IFT.Post, 0.5)
# Put those test into data.frame
testDataWide <- data.frame(Athlete = playerNames, YOYOIRL1.Pre, YOYOIRL1.Post,
v3015IFT.Pre, v3015IFT.Post)
# And print first 15 athletes
print(xtable(head(testDataWide, 15), border = T), type = "html")
| Athlete | YOYOIRL1.Pre | YOYOIRL1.Post | v3015IFT.Pre | v3015IFT.Post | |
|---|---|---|---|---|---|
| 1 | Shrestha, Ezell | 2000.00 | 2520.00 | 18.50 | 19.50 |
| 2 | Cha, Gequan | 1440.00 | 2080.00 | 20.50 | 20.00 |
| 3 | Brown, Hindav | 2360.00 | 2040.00 | 19.50 | 19.50 |
| 4 | Venegas Delarosa, Destinee | 1640.00 | 1800.00 | 19.50 | 21.50 |
| 5 | Simon, Barrington | 2240.00 | 1800.00 | 19.00 | 19.50 |
| 6 | Williams, Hyeju | 2200.00 | 2280.00 | 18.00 | 19.00 |
| 7 | Gutierrez, Sabrina | 1760.00 | 2400.00 | 17.50 | 23.00 |
| 8 | Wilder, Johannah | 1920.00 | 1640.00 | 19.00 | 22.00 |
| 9 | Martin Dean, Jillian | 1440.00 | 1960.00 | 21.00 | 22.00 |
| 10 | Thomas, Neil | 1840.00 | 2400.00 | 19.00 | 20.50 |
| 11 | Nosker, Andrew | 2080.00 | 2120.00 | 19.00 | 21.00 |
| 12 | Blackford, Matthew | 1760.00 | 2880.00 | 19.50 | 21.50 |
| 13 | Mata, Rachel | 1600.00 | 2640.00 | 18.50 | 19.50 |
| 14 | Cheng, Ryan | 1560.00 | 2440.00 | 17.50 | 21.00 |
| 15 | True, Ashley | 1720.00 | 2240.00 | 21.50 | 21.00 |
To plot the data and to do simple descriptive stats we need to reshape the data from wide format to long format using reshape2 package by Hadley Wickham
# Reshape the data
testData <- melt(testDataWide, id.vars = "Athlete", variable.name = "Test",
value.name = "Score")
# And print first 30 rows
print(xtable(head(testData, 30), border = T), type = "html")
| Athlete | Test | Score | |
|---|---|---|---|
| 1 | Shrestha, Ezell | YOYOIRL1.Pre | 2000.00 |
| 2 | Cha, Gequan | YOYOIRL1.Pre | 1440.00 |
| 3 | Brown, Hindav | YOYOIRL1.Pre | 2360.00 |
| 4 | Venegas Delarosa, Destinee | YOYOIRL1.Pre | 1640.00 |
| 5 | Simon, Barrington | YOYOIRL1.Pre | 2240.00 |
| 6 | Williams, Hyeju | YOYOIRL1.Pre | 2200.00 |
| 7 | Gutierrez, Sabrina | YOYOIRL1.Pre | 1760.00 |
| 8 | Wilder, Johannah | YOYOIRL1.Pre | 1920.00 |
| 9 | Martin Dean, Jillian | YOYOIRL1.Pre | 1440.00 |
| 10 | Thomas, Neil | YOYOIRL1.Pre | 1840.00 |
| 11 | Nosker, Andrew | YOYOIRL1.Pre | 2080.00 |
| 12 | Blackford, Matthew | YOYOIRL1.Pre | 1760.00 |
| 13 | Mata, Rachel | YOYOIRL1.Pre | 1600.00 |
| 14 | Cheng, Ryan | YOYOIRL1.Pre | 1560.00 |
| 15 | True, Ashley | YOYOIRL1.Pre | 1720.00 |
| 16 | Inouye, Connor | YOYOIRL1.Pre | 2080.00 |
| 17 | Tatum, Janice | YOYOIRL1.Pre | 1600.00 |
| 18 | Latour, Pearl | YOYOIRL1.Pre | 1720.00 |
| 19 | Tripathi, Juan | YOYOIRL1.Pre | 1360.00 |
| 20 | Moore, Michelle | YOYOIRL1.Pre | 1880.00 |
| 21 | O’Sullivan, Johanna | YOYOIRL1.Pre | 2160.00 |
| 22 | Sharp, Gregory | YOYOIRL1.Pre | 2200.00 |
| 23 | Blum, Jennifer | YOYOIRL1.Pre | 2000.00 |
| 24 | Doering, Darius | YOYOIRL1.Pre | 1200.00 |
| 25 | Sohn, Kendle | YOYOIRL1.Pre | 1880.00 |
| 26 | Horton, Grant | YOYOIRL1.Pre | 1880.00 |
| 27 | Waynewood, Nicholas | YOYOIRL1.Pre | 1640.00 |
| 28 | Pallen, Raymundo | YOYOIRL1.Pre | 1800.00 |
| 29 | Montoya, Simon | YOYOIRL1.Pre | 1480.00 |
| 30 | Clark, Bryce | YOYOIRL1.Pre | 1960.00 |
From the tables above it is easy to see the difference between wide and long data formats.
Let’s calculate simple stats using plyr package from Hadley Wickham (yes, he is a sort of celebrity in R community) and plot them using violin plots, which is great since they show the distribution of the scores
# Subset YOYOIRL1 tets
ggYOYO <- ggplot(subset(testData, Test == "YOYOIRL1.Pre" | Test == "YOYOIRL1.Post"),
aes(x = Test, y = Score))
ggYOYO <- ggYOYO + geom_violin(fill = "red", alpha = 0.5) + theme_few() + stat_summary(fun.y = mean,
geom = "point", fill = "white", shape = 23, size = 5)
# Subset 30-15IFT tets
ggIFT <- ggplot(subset(testData, Test == "v3015IFT.Pre" | Test == "v3015IFT.Post"),
aes(x = Test, y = Score))
ggIFT <- ggIFT + geom_violin(fill = "steelblue", alpha = 0.5) + theme_few() +
stat_summary(fun.y = mean, geom = "point", fill = "white", shape = 23, size = 5)
# Plot the graphs
grid.arrange(ggYOYO, ggIFT, ncol = 2)

# Calculate the summary table
testDataSummary <- ddply(testData, "Test", summarize, N = length(Score), Mean = mean(Score),
SD = sd(Score))
# Print the summary table
print(xtable(testDataSummary, border = T), type = "html")
| Test | N | Mean | SD | |
|---|---|---|---|---|
| 1 | YOYOIRL1.Pre | 150 | 1749.60 | 309.40 |
| 2 | YOYOIRL1.Post | 150 | 2246.13 | 318.41 |
| 3 | v3015IFT.Pre | 150 | 18.86 | 1.12 |
| 4 | v3015IFT.Post | 150 | 20.98 | 1.09 |
From the table above we can calculate the percent change.
YOYOIRL1.Change <- (testDataSummary$Mean[2] - testDataSummary$Mean[1])/testDataSummary$Mean[1] *
100
v3015IFT.Change <- (testDataSummary$Mean[4] - testDataSummary$Mean[3])/testDataSummary$Mean[3] *
100
print(xtable(data.frame(YOYOIRL1.Change, v3015IFT.Change), border = T), type = "html")
| YOYOIRL1.Change | v3015IFT.Change | |
|---|---|---|
| 1 | 28.38 | 11.22 |
But as mentioned in the beginning of the post, percent change is not the best way to express change and sensitivity of the tests (although it is great to impress the managers or your superiors, or claim that your test is more sensitive).
What we need to do is to calculate effect size (ES). ES takes into account the difference between the means and SD (in this case of the Pre- test, but it can also use pooled SD).
YOYOIRL1.ES <- (testDataSummary$Mean[2] - testDataSummary$Mean[1])/testDataSummary$SD[1]
v3015IFT.ES <- (testDataSummary$Mean[4] - testDataSummary$Mean[3])/testDataSummary$SD[3]
print(xtable(data.frame(YOYOIRL1.ES, v3015IFT.ES), border = T), type = "html")
| YOYOIRL1.ES | v3015IFT.ES | |
|---|---|---|
| 1 | 1.60 | 1.88 |
From the data above we can conclude that they are pretty similar and that 30-15IFT might be a bit more sensitive (or the Coach B did a better job).
Anyway, to summarize this blog post – start reporting ES alongside with percent change. If someone claims high improvements in testing scores to show how great coach he is, or how great his program is, ask to see ES or the distribution of the change scores or Pre- and Post- tests. Besides we need to also ask for SWC and TE, but more on that later.
Related Articles

Playing With Statistics [Part 2]
After a general rant in part 1 I will now try to be more pragmatic. Please note that with these posts I am not trying to impress lab coats, but rather provide an example for my fellow coaches who deal with testing and assessment. Nothing fancy, just down to earth analysis.

Quick correction in simulating Typical Error
I am awaiting review and opinions/critiques from statistics wizard Will Hopkins for my How to visualize test change scores for coaches, but even on his first look he pointed to one small error I did in simulating typical error for vertical jump. It is not huge error, but it is an error in representing typical error in measurement.
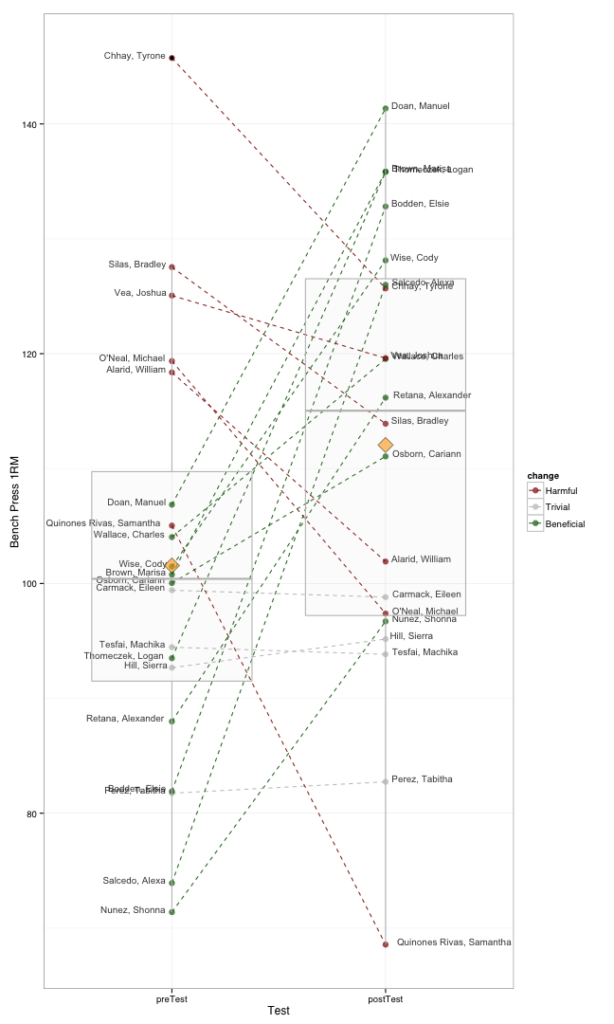
How to Visualize Test Change Scores for Coaches [Part 2]
To continue the previous How to visualize test change scores for coaches blogpost, here is another way to visualize individual change scores without falling for group averages. This way we can easily see individual ranks in both pre- and post- test, along with change score (which is also color coded). Quite easy to identify the outliers.
Non-responders: are they really?
Latest obsession of the researches is individual variation in training responses. The motivation behind this approach (known and emphasized in theory of training as individualization principle) is the creation of personalized medicine or personalized training.





Responses