A Retrospective Examination of Machine Learning (ML) Techniques for Predicting Cycle Ergometer Peak Performance in a Clinical Setting of Cancer Survivors – Part 2
Previous Part:
 Click here to read the part one of this article series »
Click here to read the part one of this article series »
Before we delve into the intricacies of the second part, let’s take a moment to review the key points from the first article in the series.
Given the detrimental effects of cancer and its treatments on physical performance, there’s a pressing need for precise assessment tools to tailor exercise programs for survivors. Thus, the application of machine learning (ML) techniques to predict peak physical performance in cancer survivors, focusing on cycle ergometer testing, constituted the central theme of this series of articles.
The study employed two popular ML frameworks, Scikit-Learn and Fastai, to analyze data from 1712 cancer patients, using regression, classification, and deep learning models. Key models of the first article included Linear Regression (LR), Support Vector Regressor (SVr), Random Forest Regressor (RFr). Data processing adhered to the 80/20 principle, focusing on data preparation and mining to avoid “garbage in, garbage out” pitfalls.
The dataset comprised anonymized data on 1127 females and 585 males, with detailed measurements including sex, age, body height, and weight. Preprocessing aimed to identify and correct inconsistencies, utilizing four predictor variables (sex, age, body height, and body weight) against outcomes like peak watt and fitness performance level (FPL).
Model validation involved 10-fold cross-validation and fine-tuning via the GridSearchCV function, emphasizing the importance of supervised learning methodologies. The study provided insights into the predictive accuracy of various ML models, with notable results showing that the Random Forest Regressor (RFr) outperformed others in predicting peak physical performance, as indicated by the lowest root mean square error (RMSE).
The efficacy and predictive abilities of each model are detailed as follows:
- Linear Regression (LR) showcased a root mean square error (RMSE) of 36.42 Watt, indicating its utility in predicting peak watt performance, albeit with room for improvement.
- Support Vector Regressor (SVR) achieved an RMSE of 34.87 Watt, slightly trailing behind RFr but offering competitive performance.
- Random Forest Regressor (RFr) emerged as the most effective, with the lowest 34.12 Watt, underscoring its superiority in accuracy for this application.
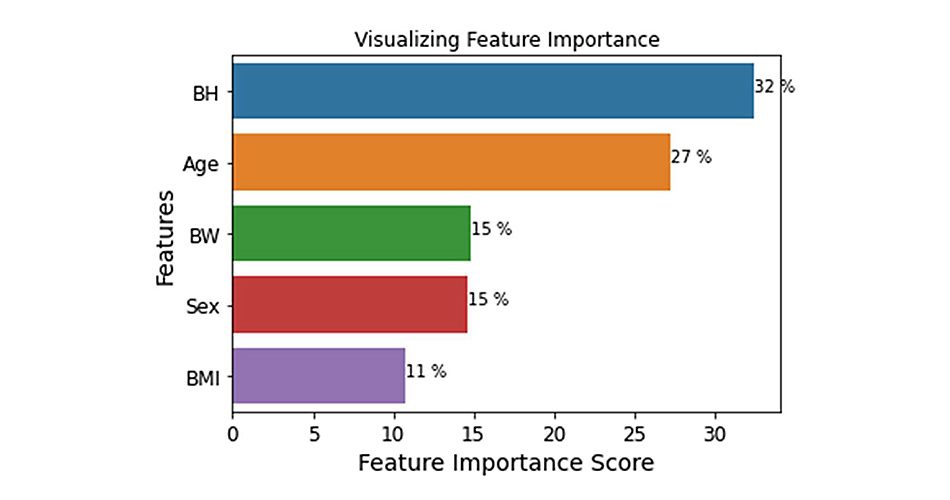
Feature importance analysis revealed body height and age as significant predictors, while permutation importance analysis highlighted body weight’s relevance. This study not only validates the potential of ML in enhancing physical performance assessments for cancer survivors but also sets a precedent for further research into the application of ML in personalized rehabilitation strategies. The series promises continued exploration into classification models and deep learning techniques, aiming to deepen the understanding and application of ML in oncological physical rehabilitation.
The second article in this trilogy offers an in-depth exploration of machine ML algorithms used to predict fitness levels in cancer patients, emphasizing classification algorithms to categorize patients into three fitness performance groups: bad, moderate, and good. This comprehensive analysis aims to provide an accurate classification of patient fitness levels, contributing significantly to personalized patient care.
Preprocessing and feature engineering
The main challenge addressed here was the issue of an imbalanced dataset, where the number of observations for each category was not evenly distributed. This can be seen in Table 2 of the previous article, where the categorical outcome variable shows uneven representation. Specifically, the “Bad” class comprises only 19% and 12% of the observations when compared to the “Moderate” and “Good” classes, respectively. Additionally, the “Moderate” class has 36% fewer observations than the “Good” class. To tackle this imbalance, the SMOTENC (Synthetic Minority Oversampling Technique for Nominal and Continuous) method was applied. This approach was used in conjunction with Scikit Learn’s (LogR, SVC, and RFc) and Fastai CNN classification models to prevent overestimation of performance due to dataset imbalance. Essentially, SMOTENC creates new data points in under-represented classes using the k-nearest neighbors’ algorithm. For each classification model, the k_neighbors parameter was individually adjusted for both training and test datasets, ensuring that an optimal number of neighbors is used to generate synthetic samples effectively for each model.
Validation
The StratifiedKFold function was applied to Scikit Learn’s classification models to preserve class ratio consistency in response variables during cross-validation.
As we talked about earlier, all the models we’re looking at in this study use a type of learning called supervised learning. This means they learn from a dataset that’s already been sorted and labeled, which includes different types of data like numbers and categories.
Also, remember we said we’d split this topic into three articles? Each one will focus on a different machine learning (ML) method: regression, classification, and deep learning. In this essay, we’ll start off with an easy intro to classification models.







Responses