Statistics 101 – Introduction to ‘Model Thinking’
I am just reading Data Science for Business book, which is by the way great, and finishing Discovering Statistics Using R. Both of these provide interesting viewpoint on building models.
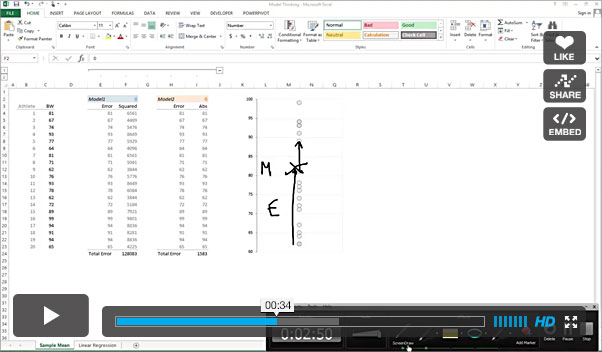
In most other stats books, linear regression and correlation are explained by trying to find a linear relationship between variables – using the ‘model thinking’ viewpoint we are trying to fit the model to the data by optimizing its parameters.
I know this is a chicken vs. egg problem, but I like this viewpoint much more, maybe because I am prone to simulations and optimizations more than math, especially matrix algebra.
I am also reading and learning more about machine learning (great presentation HERE) and I find this article quite interesting showing the difference between machine learning/data mining and general stats approach.
Anyway, the video below is my attempt to explain this ‘model thinking’ idea and optimization approach. Underneath it you can find and download the Excel workbook.








Responses